Objective-C 코드 (bytes는 NSData 클래스 객체에서 bytes를 호출하여 얻은 데이터 포인터)
for(uint32_t i = 0; i < dataSize - 4; i++)
{
uint32_t startCode = *(uint32_t *)(bytes + i);
if(startCode == 0x01000000)
{
[points addObject:[NSValue valueWithPointer:bytes + i]];
[nalSizes addObject:[NSNumber numberWithInt:4]];
i += 3;
}
if((startCode & 0x00FFFFFF) == 0x00010000)
{
[points addObject:[NSValue valueWithPointer:bytes + i]];
[nalSizes addObject:[NSNumber numberWithInt:3]];
i += 2;
}
}
Swift 코드 (3.0으로 빌드, streamData는 Data 클래스의 객체)
streamData.withUnsafeBytes { (p8: UnsafePointer) in
while i < count
{
if p8.advanced(by: i + 0).pointee == 0 && p8.advanced(by: i + 1).pointee == 0
{
if p8.advanced(by: i + 2).pointee == 0 && p8.advanced(by: i + 3).pointee == 1
{
offsets.append(i)
nalSizes.append(4)
i += 4
continue
}
if p8.advanced(by: i + 2).pointee == 1
{
offsets.append(i)
nalSizes.append(3)
i += 3
continue
}
}
i += 1
}
}
H264에서 NAL 헤더를 찾는 코드이다. 어쩌다보니 기존에 Objective-C로 코드를 만들어놓은걸 Swift로 옮기다보니... 생각보다 삽질을 많이하게되었다. 프레임워크는 동일하지만 Swift는 기본적으로 포인터 연산을 지원하지않기때문에 C에서의 구조체, 바이너리 데이터를 int형식으로 형변환하여 비교하는 등의 연산에서 자유롭지않아보인다. 동일한 LLVM에서 컴파일되고 1:1 호환 가능하다고는하지만 위와같은 사항 외에도 언어의 특성이있어서 목적은 동일하지만 결국은 코드의 구조는 달라졌다.
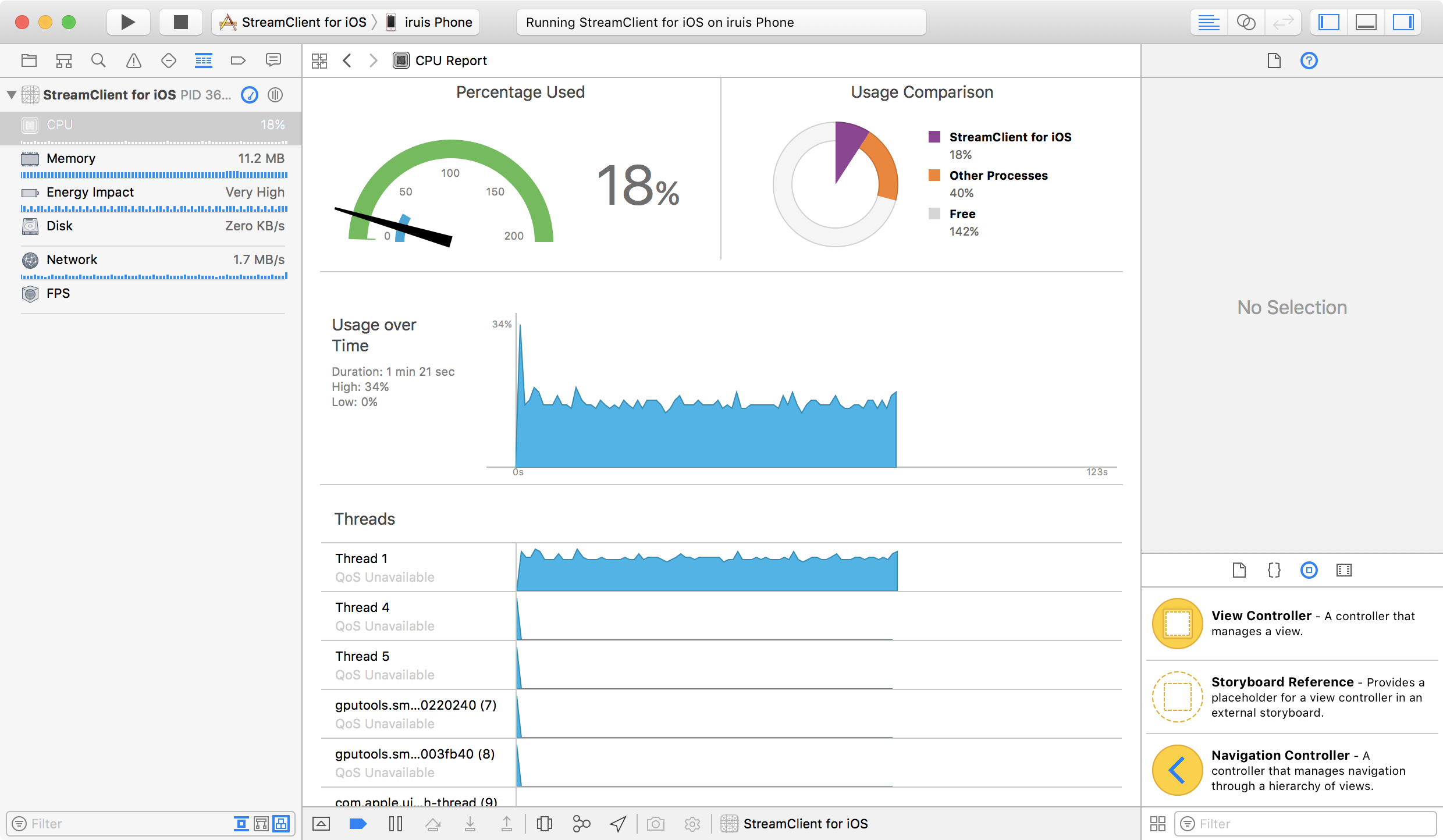
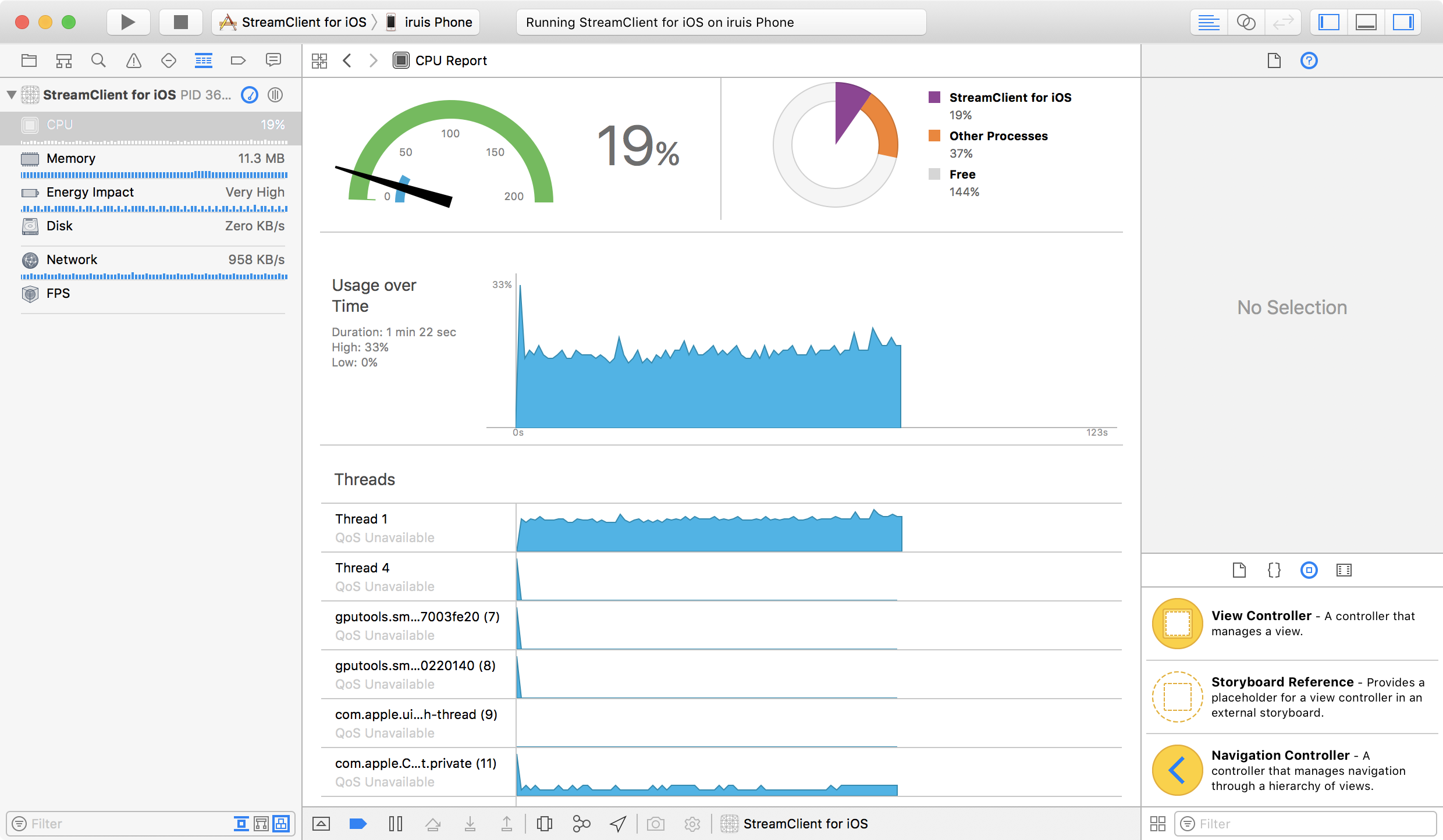
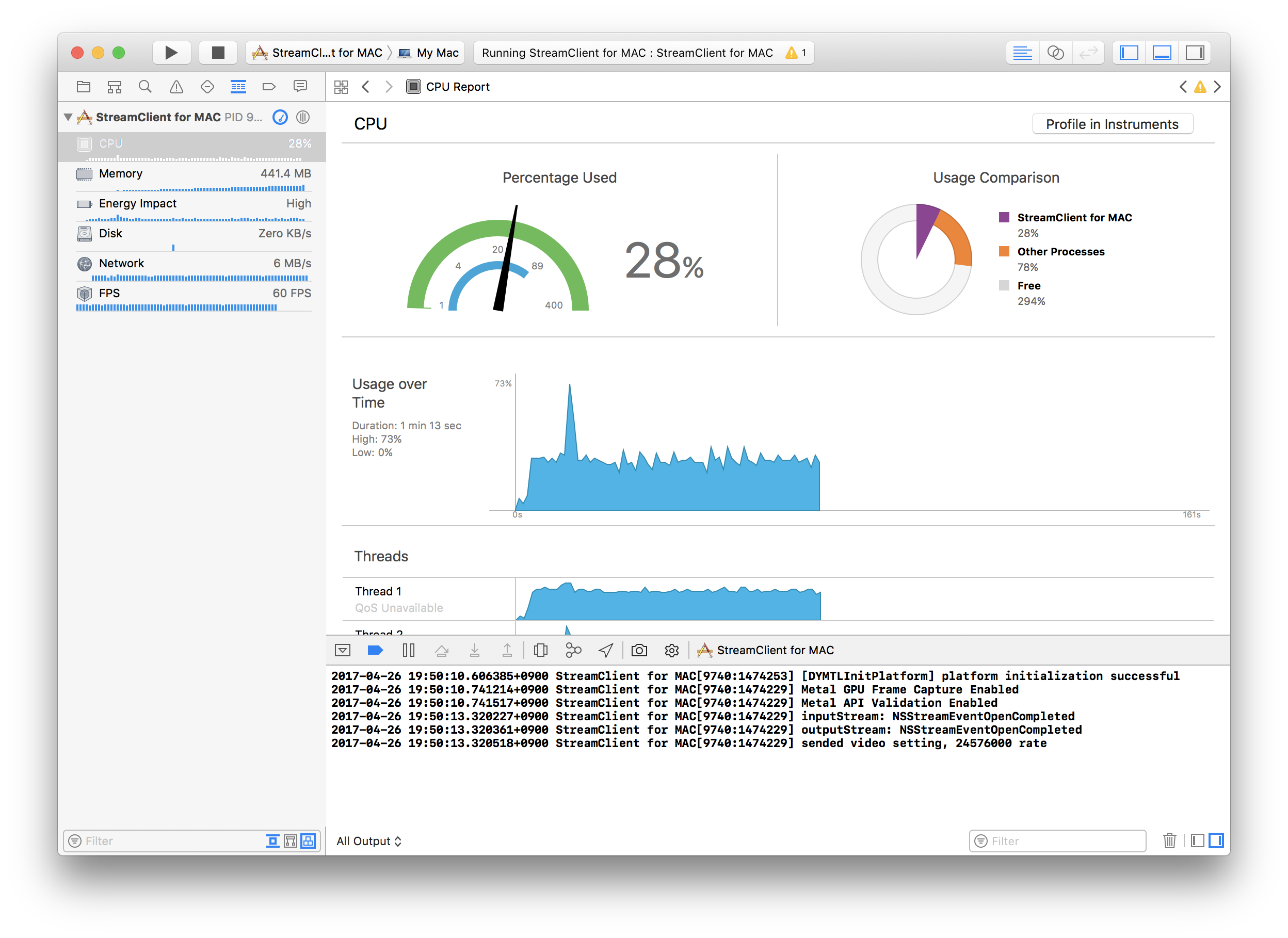
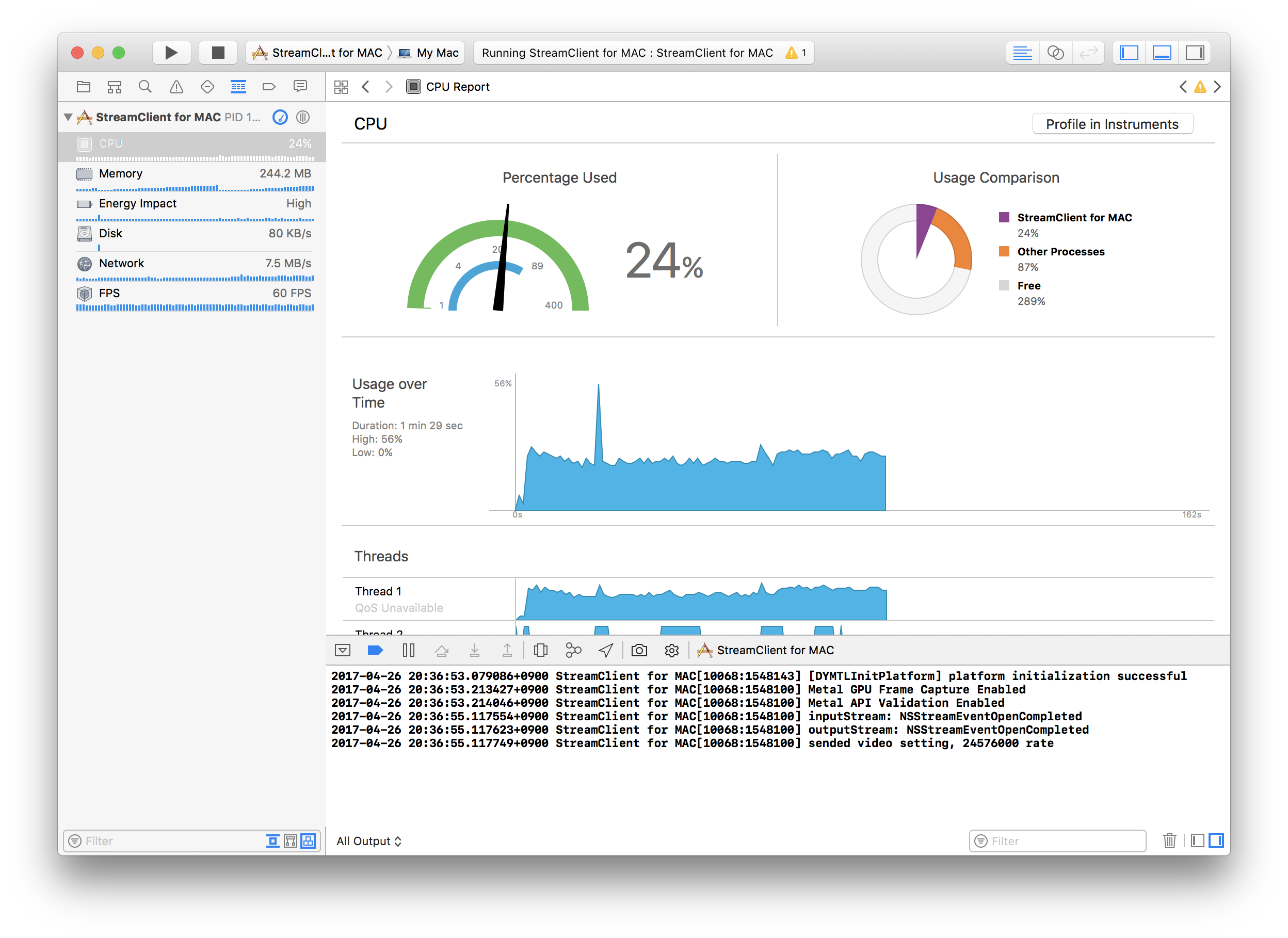
딱봐도 Swift의 코드가 비효율적으로 보이지만 초당 1메가정도의 데이터에서 CPU점유율을 보면 1~2%정도만 더 Swift에서 많이 사용한다. 아직 릴리즈 빌드는 찾아본적없어서 export하게되면 또 차이날지는 모르겠지만... 현재로서는 약 2~3시간 삽질을 한 결과 위 코드가 Objective-C의 코드와 가장 근접한 CPU 사용률을 보이는 코드이다.
아래는 순서대로 Objective-C, Swift 코드에서의 CPU 사용률